介绍
收集和可视化数据是做出关于服务器和项目的明智决策的重要方式。
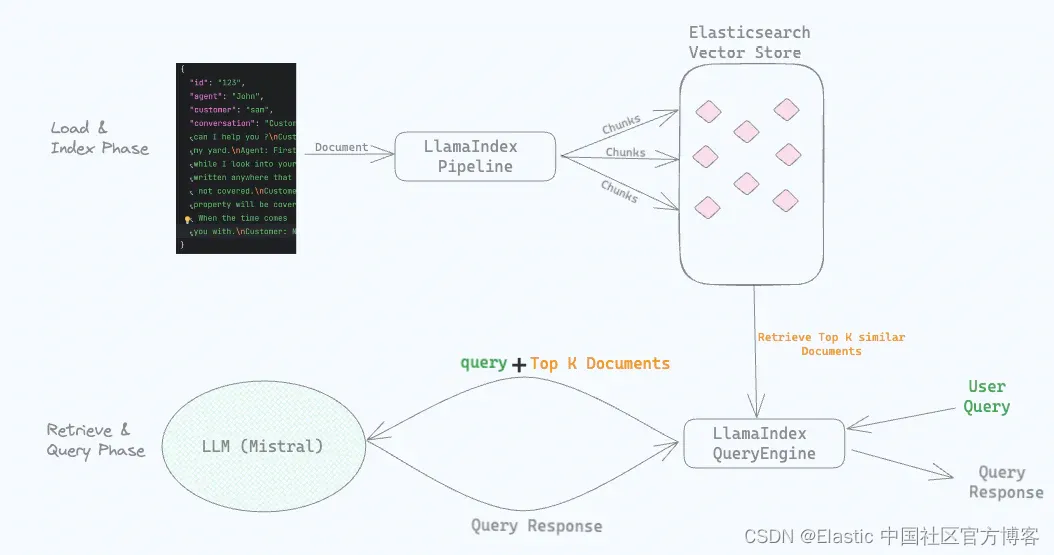
在之前的指南中,我们讨论了如何安装和配置 Graphite 来可视化我们服务器上的数据。然而,我们没有一个很好的方法来收集或者传递数据到 Graphite。
在本指南中,我们将讨论安装和使用 collectd,这是一个系统统计信息收集器,可以收集和组织关于服务器和运行服务的指标。
我们将向您展示如何安装和配置 collectd 来传递数据到 Graphite 进行渲染。我们将假设您已经在 Ubuntu 14.04 服务器上安装并运行了 Graphite,就像我们在上一篇指南中向您展示的那样。
安装 Collectd
我们要做的第一件事是安装 collectd。我们可以从默认仓库获取它。
刷新本地软件包索引,然后输入以下命令进行安装:
sudo apt-get update
sudo apt-get install collectd collectd-utils
这将安装守护程序和一个辅助控制界面。我们仍然需要配置它,以便它知道将收集的数据传递给 Graphite。
配置 Collectd
首先,使用 root 权限在编辑器中打开 collectd 配置文件:
sudo nano /etc/collectd/collectd.conf
我们应该设置的第一件事是我们所在机器的主机名。Collectd 可以用于将信息发送到远程 Graphite 服务器,但是在本指南中我们将在同一台机器上使用它。您可以选择任何您喜欢的名称:
Hostname "<span class="highlight">graph_host</span>"
如果您已经配置了真实的域名,您可以跳过这一步,只需保留 FQDNLookup,这样服务器将使用 DNS 系统获取正确的域名。
您可能会注意到有一个 “Interval” 参数,这是 collectd 在查询主机上的数据之前等待的时间间隔。默认设置为 10 秒。如果您在 Graphite 文章中跟随操作,您会注意到这是 Graphite 跟踪统计信息的通常最短间隔。这两个值必须匹配才能可靠记录数据。
接下来,我们立即进入 Collectd 将收集信息的服务。Collectd 通过使用插件来实现这一点。大多数插件用于从系统中读取信息,但也有插件用于定义发送信息的位置。Graphite 就是其中之一。
对于本指南,我们将确保启用以下插件。您可以注释掉任何其他插件,或者如果您想在主机上尝试它们,也可以开始配置它们:
LoadPlugin apache
LoadPlugin cpu
LoadPlugin df
LoadPlugin entropy
LoadPlugin interface
LoadPlugin load
LoadPlugin memory
LoadPlugin processes
LoadPlugin rrdtool
LoadPlugin users
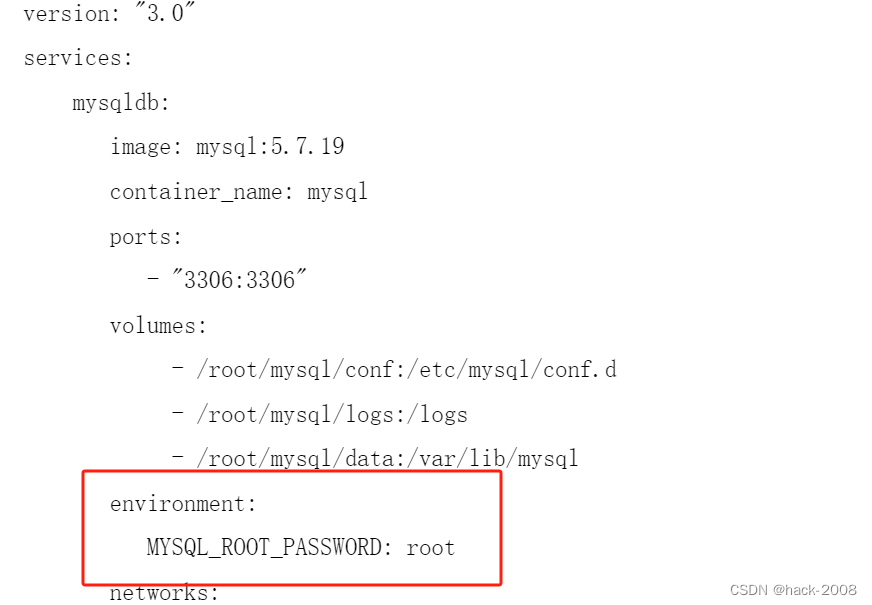
LoadPlugin write_graphite
其中一些需要配置,而另一些则可以直接使用。
继续向下滚动文件,我们来到每个插件的配置部分。插件通过为每个配置部分定义一个 “块” 来进行配置。这在某种程度上类似于 Apache 在块内部对指令进行分隔。由于大多数插件的工作方式都很好,我们只会看一些插件的配置。
我们启用了 Apache 插件,因为我们已经安装了 Apache 来提供 Graphite 服务。我们可以使用一个简单的部分来配置 Apache 插件,看起来像这样:
<Plugin apache>
<Instance "Graphite">
URL "http://<span class="highlight">domain_name_or_IP</span>/server-status?auto"
Server "apache"
</Instance>
</Plugin>
在生产环境中,您可能希望将服务器统计信息保护在身份验证层后面。您可以查看文件中此部分的注释代码,以了解它是如何工作的。为简单起见,我们将演示一个不需要身份验证的开放设置。
我们将稍后创建 Apache 的 server-status 页面,以便为我们提供所需的详细信息。
对于 df 插件,它告诉我们磁盘有多满,我们可以添加一个简单的配置,看起来像这样:
<Plugin df>
Device "/dev/<span class="highlight">vda</span>"
MountPoint "/"
FSType "ext3"
</Plugin>
您应该将设备指向系统上驱动器的设备名称。您可以通过在终端中输入以下命令来找到这个名称:
df
选择您希望监视的网络接口:
<Plugin interface>
Interface "<span class="highlight">eth0</span>"
IgnoreSelected false
</Plugin>
最后,我们来到 Graphite 插件。这将告诉 collectd 如何连接到我们的 Graphite 实例。使部分看起来像这样:
<Plugin write_graphite>
<Node "<span class="highlight">graphing</span>">
Host "localhost"
Port "2003"
Protocol "tcp"
LogSendErrors true
Prefix "collectd."
StoreRates true
AlwaysAppendDS false
EscapeCharacter "_"
</Node>
</Plugin>
这告诉我们的守护程序如何连接到 Carbon 以传递其数据。我们指定它应该在本地计算机上的 2003 端口上查找,这是 Carbon 用于监听 TCP 连接的端口。
接下来,我们告诉它使用该协议可靠地传递数据给 Carbon。我们告诉它记录有关传递的错误,并设置数据的前缀。由于我们以句点结尾,这台主机的所有 collectd 统计信息将存储在 “collectd” 目录中。
存储速率确定是否在传递之前将统计信息转换为仪表。如果启用,追加数据源行将在启用时将节点名称附加到我们的指标中。转义字符确定如何转换具有句点的某些值,以避免 Carbon 将它们拆分为目录。
完成后保存并关闭文件。
配置 Apache 报告统计信息
在我们的配置文件中,我们已经启用了 Apache 统计信息跟踪。但是我们仍然需要配置 Apache 来允许这一功能。
在我们为 Graphite 启用的 Apache 虚拟主机文件中,我们可以添加一个简单的位置块,告诉 Apache 报告统计信息。
在文本编辑器中打开文件:
sudo nano /etc/apache2/sites-available/apache2-graphite.conf
在“content”位置块下面,我们将添加另一个块,以便 Apache 在 /server-status 页面提供统计信息。添加以下部分:
Alias /content/ /usr/share/graphite-web/static/
<Location "/content/">
SetHandler None
</Location>
<Location "/server-status">
SetHandler server-status
Require all granted
</Location>
ErrorLog ${APACHE_LOG_DIR}/graphite-web_error.log
完成后保存并关闭文件。
现在,我们可以重新加载 Apache 以访问新的统计信息:
sudo service apache2 reload
我们可以通过在网页浏览器中访问页面来检查一切是否正常工作。只需在我们的域名后面加上 /server-status:
http://<span class="highlight">domain_name_or_IP</span>/server-status
您应该会看到类似以下的页面:
!server stats
设置存储模式和聚合
现在我们已经配置了 collectd 来收集有关您的服务的统计信息,我们需要调整 Graphite 以正确处理收到的数据。
让我们首先创建一个存储模式定义。打开存储模式配置文件:
sudo nano /etc/carbon/storage-schemas.conf
在文件中,我们需要添加一个定义,以规定信息保留的时间以及各个级别的数据详细程度。
我们将告诉 Graphite 以十秒的间隔在一天内存储 collectd 信息,在七天内以一分钟的间隔存储,在一年内以十分钟的间隔存储。
这将为我们提供最近活动的详细信息和长期趋势的一般趋势之间的良好平衡。Collectd 传递其指标,以字符串 collectd 开头,因此我们将匹配该模式。
我们可以通过添加以下行来添加所描述的策略。请记住,在默认策略之上添加这些行,否则它们将永远不会被应用:
[collectd]
pattern = ^collectd.*
retentions = 10s:1d,1m:7d,10m:1y
完成后保存并关闭文件。
重新加载服务
现在 collectd 已经配置,Graphite 知道如何处理其数据,我们可以重新加载服务。
首先,重新启动 Carbon 服务。最好使用“stop”命令,然后在重新启动之前等待几秒钟,而不是使用“restart”命令。这可以确保在重新启动之前完全刷新数据:
sudo service carbon-cache stop ## 在此等待几秒钟
sudo service carbon-cache start
Carbon 服务再次运行后,我们可以对 collectd 执行相同的操作。该服务可能尚未运行,但这将确保它正确处理数据:
sudo service collectd stop
sudo service collectd start
完成后,您可以再次访问您的域名,您应该会看到一个包含 collectd 信息的新树:
!collectd tree
结论
我们的 collectd 配置已经完成,我们的统计信息已经被记录!现在,我们已经配置了一个守护进程来跟踪我们的服务器和服务。
我们可以根据需要配置或编写 collectd 的其他插件。其他具有 collectd 的服务器也可以将数据发送到我们的 Graphite 服务器。Collectd 主要用于收集有关常见服务和整个机器的统计信息。
在下一篇文章中,我们将设置 StatsD,这是一个可以在将数据刷新到 Graphite 之前缓存数据的服务。这将使我们能够解决在发送统计信息过快时出现数据丢失的问题,这是我们在上一篇文章中描述的。它还将为我们提供一个界面,用于跟踪我们自己的程序和项目中的统计信息。